微软新安全系统捕捉客户AI应用程序幻觉 - 安全系统新闻
"我们知道客户并不都精通提示注入攻击或仇恨内容,因此评估系统会生成模拟这些类型攻击所需的提示。然后,客户可以获得评分并看到结果,"她说。
这有助于避免人工智能生成器因不良或意外反应而引发的争议,比如最近出现的明显伪造名人(微软的 Designer 图像生成器)、历史上不准确的图像(Google Gemini)或马里奥驾驶飞机撞向双子塔(Bing)等事件。
三项功能:提示屏蔽(Prompt Shields)可阻止提示注入或来自外部文档的恶意提示,这些提示会指示模型违背其训练;基础检测(Groundedness Detection)可发现并阻止幻觉;安全评估(Safety evaluations)可评估模型的漏洞。用于引导模型实现安全输出和跟踪提示以标记潜在问题用户的其他两项功能即将推出。
无论是用户输入的提示信息,还是模型正在处理的第三方数据,监控系统都会对其进行评估,看是否会触发任何禁用词或有隐藏提示,然后再决定是否将其发送给模型回答。之后,系统会查看模型的回答,并检查模型是否幻觉了文件或提示中没有的信息。
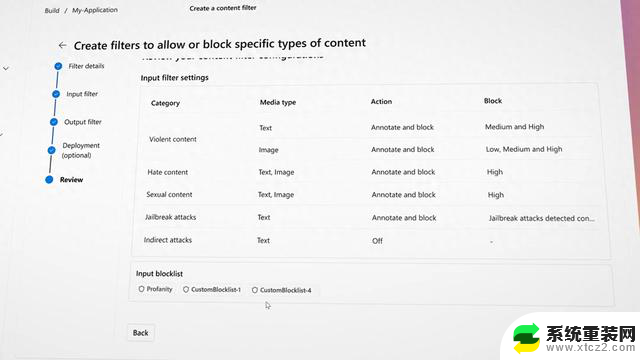
在Google Gemini图片的案例中,为减少偏见而制作的过滤器产生了意想不到的效果,微软表示,在这一领域,其 Azure AI 工具将允许更多的定制控制。伯德承认,有人担心微软和其他公司可能会决定什么适合或不适合人工智能模型。因此她的团队为Azure客户添加了一种方法,可以切换过滤模型看到并阻止的仇恨言论或暴力。
未来,Azure 用户还可以获得试图触发不安全输出的用户报告。伯德说,这可以让系统管理员找出哪些用户是自己的红队成员,哪些可能是怀有更多恶意的人。
伯德说,这些安全功能会立即"附加"到 GPT-4 和其他流行的模型(如 Llama 2)上。 不过,由于 Azure 的模型花园包含许多人工智能模型,使用较小、较少使用的开源系统的用户可能需要手动将安全功能指向这些模型。
微软一直在利用人工智能来加强其软件的安全性,尤其是随着越来越多的客户开始对使用 Azure 访问人工智能模型感兴趣。该公司还努力扩大其提供的强大人工智能模型的数量,最近与法国人工智能公司 Mistral 签订了独家协议,在 Azure 上提供 Mistral Large 模型。
微软新安全系统捕捉客户AI应用程序幻觉 - 安全系统新闻相关教程
- 微软面向Win10发布9月累积更新,重点修复安全问题,保障操作系统安全性
- 微软发布Windows 11 系统更新KB5035950:Copilot全新功能大揭秘
- 微软Windows Update未来可用于重新安装Windows 11:全新功能将使系统恢复变得更加简单
- 微软全面淘汰Win10和部分11用户,强制升级最新系统,你是否已做好准备?
- 微软网络安全活动:“全球蓝屏”始作俑者将参会,了解最新安全技术!
- 微软Windows 11开始菜单全新布局改进,用户体验提升
- 微软联合OpenAI、谷歌等公司设立1000万美元AI安全基金,保障人工智能安全的重要举措
- 微软反对苹果针对欧盟应用程序商店的新计划
- Win11遇冷,Win10坚守安全更新成本分析: Win11遇冷,Win10坚守安全更新成本分析:Win10仍是企业首选,Win11更新成本凸显
- 微软正式面向企业和政府客户推出 Office LTSC 2024,提供稳定安全的办公解决方案
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐