微软Phi-3小模型科林详细测试报告
关于 Phi 系列模型
Phi 是由微软 AI 研究院开发的一个开源「小型语言模型」,可商用,卖点是小,需要的资源少。
今天发布的 Phi-3
新发布的 Phi-3,包括 Phi-3-Mini、Phi-3-Small 和 Phi-3-Medium。
其中,Phi-3-Mini 最小,只有 3.8B 的参数,但在重要的基准测试中的表现可与大型模型如 Mixtral 8x7B 和 GPT-3.5 媲美。
而更大的 Small 和 Medium ,在扩展的数据集的加持下就更牛逼了。
第 1 部分刚刚发布的 Phi-3就在中午,在 arXiv 上悄咪咪的出现了一篇论文《Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone》 ,即:《Phi-3 技术报告:一个能跑在手机上的牛逼模型》,地址在这:https://arxiv.org/abs/2404.14219,宣示着 Phi-3 的到来。
模型概述Phi-3-mini
3.8B 的参数,3.3T token 训练数据。在多个学术基准测试中,Phi-3-mini 性能接近或等同于市场上的大型模型,例如在 MMLU 测试中得分为 69%,在 MT-bench 测试中得分为 8.38 分。
Phi-3-small 和 Phi-3-medium
这两个是扩展模型:
- Small 是 7B 参数,4.8T token 训练数据,MMLU 75%,MT-bench 8.7 分。
- Medium 是 14B 参数,4.8T token 训练数据,MMLU 78%,MT-bench 8.9 分。
核心优势小,特别小
小到在手机上就能跑:在 iPhone 上,每秒能出 16 token 的信息,相当于 12 个单词
本地跑,意味着很多
提供 GPT-3.5 水平的输出,还不需要联网,意味着很多东西:离线部署、隐私保护... 很多事情的玩法彻底变了
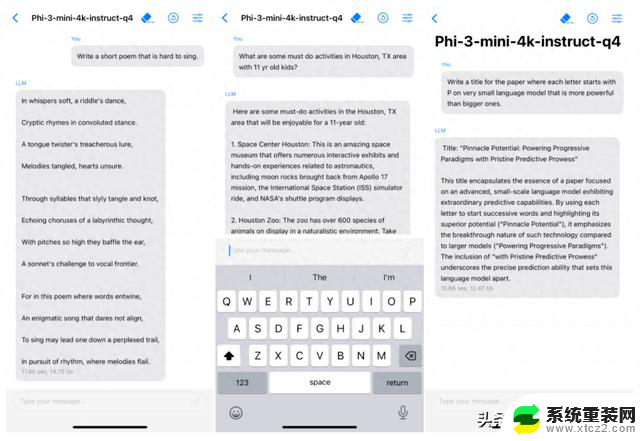
文化有限
脑袋小了,装的东西就少,在面对需要广泛事实知识支撑的任务(如 TriviaQA 测试)时尤为明显,表现为性能下降、幻觉提升。这种问题可以通过与搜索引擎集成来弥补,利用搜索引擎提供额外的信息支持,增强模型的知识库和应对能力。
只懂英文
Phi-3-mini 还目前只能处理英语。但 Small/Medium 已经包含了更多的多语言数据,相信以后会慢慢迭代的。
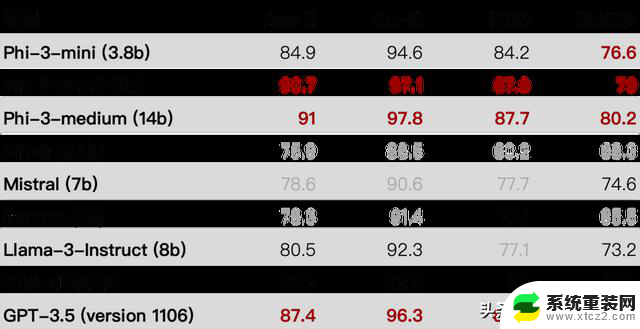
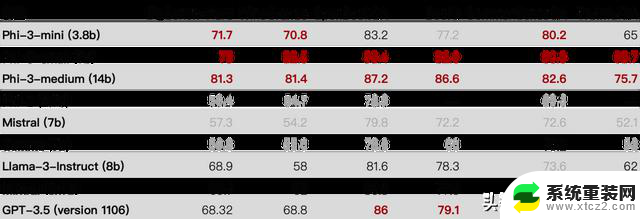
第 2 部分技术性能从分数上看,仅仅是 Phi-3-mini 这一最小版本,就已经全面超越刚刚发布的Llama 3了。对此,我人肉整理了个 Excel...以及所有评比的 Excel

基准测试
Phi-3-mini 在大规模多任务语言理解(MMLU)上的得分为69%,在 MT-bench 上的得分为8.38,与 Mixtral 8x7B 和 GPT-3.5 等大型模型具有竞争力。Phi-3-small(7B)和 phi-3-medium(14B)性能更强,在 MMLU 上分别达到 75% 和 78%,在 MT-bench 上分别为 8.7 和 8.9。各种比较,见下图: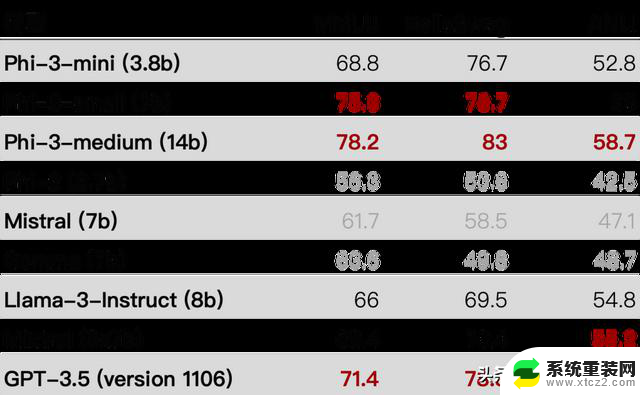


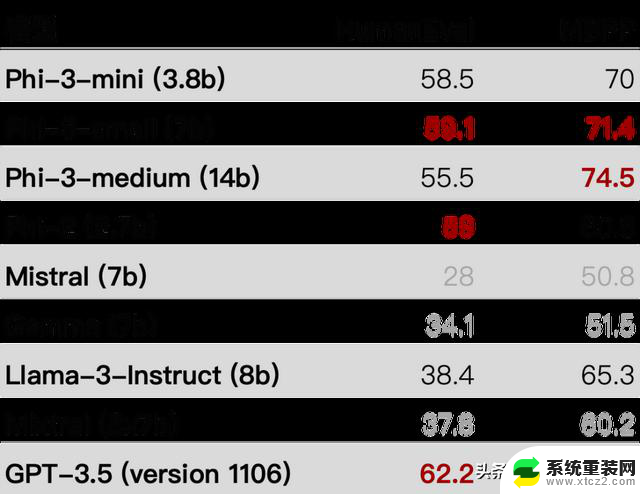

Phi-3-mini 的架构
采用了为移动设备部署优化的 Transformer 解码器架构,默认 4k 上下文,可通过 LongRope 系统扩展至最多128K,以支持更长上下文的处理需求。Phi-3-mini 在结构设计上与 Llama-2 模型相似,使用了相同的分词器。这使得为 Llama-2 系列开发的各种软件包可以直接与 Phi-3-mini 兼容。Small 和 Medium
这两个模型引入了分组查询注意力机制和块状稀疏注意力机制等先进配置,这些配置有助于在保持长期上下文检索性能的同时,最大限度地减少键值(KV)缓存的占用。
数据训练
使用高水平的网页数据和合成数据进行训练。分为两个阶段进行训练:第一阶段以网页源数据为主,旨在教授通用知识和语言理解能力;第二阶段结合更多严格筛选的网页数据和一些合成数据,培养模型的逻辑推理能力和特定技能。
低资源占用
对于 Phi-3-mini,内存占用约为1.8GB,能够在 iPhone 14 上配备 A16 Bionic 芯片的设备上运行,离线状态下 12+ token/s。
第 3 部分好玩的思路Azure AI Platform 的副总裁 Eric Boyd,在接受 The Verge 采访的时候,提到里以下几个信息:
Phi-3 的训练方法受到儿童学习方式的启发,采用了“课程”式的训练训练灵感源自孩子们从睡前故事、简化的书籍和谈论更大主题的句子结构中学习由于缺乏足够的儿童读物,他们列出了一个超过 3000 个单词的清单,并要求一个LLM制作“儿童读物”来教导 Phi-3虽然 Phi-3 在编码和推理方面表现出色,但由于其训练数据和模型规模的限制,其知识广度不及像 GPT-4 这样的大型模型。Phi-3 虽然能够解决特定任务,但无法像更大的模型那样覆盖广泛的主题和内容公司发现 Phi-3 等小型模型更适用于定制应用,尤其是对于那些数据集较小的企业而言。这些小型模型不仅价格相对实惠,而且能够更好地适应有限的数据集,提供高性能的解决方案微软Phi-3小模型科林详细测试报告相关教程
- 微软Win11发现国产开源大模型,RWKV官方回应:未收到任何报酬
- 三星旗舰平板天玑9300处理器测试:告别骁龙,迎接发哥?
- 字节跳动大模型训练被“投毒”,微软宣布终止中国个人Azure OpenAI服务AI周报
- 微软做广告,为什么有“钱途”?解析微软广告的商业价值
- AMD单季营收68亿美元,净利润15亿美元,收购ZT Systems详细报告
- 微软做广告,为什么有“钱途”?探索微软广告的商业潜力
- OpenAI和微软被指窃取他人作品训练AI模型,遭集体诉讼
- 微软与OpenAI联手阻止黑客使用AI大模型,估值达800亿美元
- 离谱的微软 | 财报季:微软财报季度表现出人意料!
- 微软推出AI模型“MAI-1”与谷歌、OpenAI竞争:最新消息
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐