谁能成为英伟达平替?找到最适合的替代品
谁能替代英伟达?
在数据中心GPU领域,2023年英伟达出货量达到376万片,占据全球近98%的市场份额,可以说无人匹敌。
AI芯片也被称为AI加速器或计算卡,是专门用于处理人工智能应用中的大量计算任务的模块,主要包括图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)等。
根据Gartner的数据,2023年AI芯片市场规模将达到534亿美元,比2022年增长20.9%,2024年将增长25.6%,达到671亿美元。到2027年,AI芯片营收预计将是2023年市场规模的两倍以上,达到1194亿美元。
各大巨头公司上演的算力军备竞赛无疑成为了推高AI芯片市场的强劲动力。
从2024年起,主流大模型几乎都在千亿参数之上,Llama3有4000亿参数、GPT4有1.8万亿参数。万亿参数大模型,对应着万卡以上规模的超大算力集群。
OpenAI掌握着至少达五万片的英伟达高端GPU,Meta自建了24576片H100组成的超万卡集群。谷歌则有26000片H100构成的A3超级计算机……超过有4万家企业采购了英伟达GPU,像Meta、微软、亚马逊、谷歌总计贡献了其40%的收入。
财报显示,英伟达毛利率达到71%,其中,A100和H100系列的毛利率更是高达90%。英伟达作为一家硬件公司,有着比互联网公司更高的毛利率。
据悉,英伟达用于数据中心的AI芯片每片售价为2.5万-4万美元,是传统产品的7-8倍。研究公司Omdia咨询总监Kazuhiro Sugiyama表示,英伟达产品价格高昂,这对想投资AI的公司来说是一个负担。
高昂的售价也让不少大客户开始寻找替代方案。7月30日,苹果宣布其AI模型用8000片谷歌TPU来训练。OpenAI首颗芯片也于今日曝光,将采用台积电最先进的A16埃米级工艺,专为Sora视频应用打造。
全球范围内,AI芯片明星创业公司、独角兽纷纷涌现,试图从英伟达口中虎口夺食。这其中,既有华人背景的独角兽SambaNova以及刚刚崭露头角的Etched。也有OpenAI CEO奥特曼投资的独角兽Cerebras Systems正在冲刺IPO,软银集团总裁孙正义则是在去年将ARM成功上市之后,今年7月又收购了英国AI芯片公司Graphcore,试图打造下一个英伟达。
斯坦福系华人打造的AI芯片独角兽SambaNova
8月27日,美国AI芯片初创公司SambaNova首次详细介绍了其新推出的全球首款面向万亿参数规模的人工智能(AI)模型的AI芯片系统——基于可重构数据流单元 (RDU) 的 AI 芯片 SN40L。
据介绍,基于SambaNova的SN40L的8芯片系统,可以为5万亿参数模型提供支持,单个系统节点上的序列长度可达256k+。对比英伟的H100芯片,SN40L不仅推理性能达到了H100的3.1倍,训练性能也达到了H100的2倍,总拥有成本更是仅有其1/10。
公司的三位联合创始人都是斯坦福背景,其中CEO Rodrigo Liang是前Sun/甲骨文工程副总裁,另外两位联合创始人都是斯坦福教授,此外团队中还有不少华人工程师。
SambaNova目前估值50亿美元(约365亿元人民币),累计完成了6轮总计11亿美元的融资,投资方包括英特尔、软银、三星、Google Venture等。

他们不仅在芯片上要挑战英伟达,业务模式上也要比英伟达走得更远:直接参与帮助企业训练私有大模型。并且芯片不单卖,而是出售其定制的技术堆栈,从芯片到服务器系统,甚至包括部署大模型。
其对于目标客户的野心更是很大——瞄准世界上最大的2000家企业。目前,SambaNova的芯片和系统已获得不少大型客户,包括世界排名前列的超算实验室,日本富岳、美国阿贡国家实验室、劳伦斯国家实验室,以及咨询公司埃森哲等。
Rodrigo Liang认为,大模型与生成式AI商业化的下一个战场是企业的私有数据,尤其是大企业。最终,企业内部不会运行一个GPT-4或谷歌Gemini那样的超大模型,而是根据不同数据子集创建150个独特的模型,聚合参数超过万亿。
这一策略与GPT-4和谷歌Gemini等做法形成鲜明对比,巨头大多希望创建一个能泛化到数百万个任务的巨型模型。
两个00后哈佛辍学生打造的AI芯片公司Etched
Etched创始人是两个哈佛00后辍学生。Gavin Uberti曾在OctoML和Xnor.ai担任要职,Chris Zhu则是华裔,除了在哈佛大学担任过计算机科学的教学研究员外,还有在亚马逊等公司的实习经历。
他们在ChatGPT还没有发布的时候就看好大模型方向,于是在2022年从哈佛大学退学,与 Robert Wachen 和前赛普拉斯半导体公司首席技术官 Mark Ross联手创办了Etched,打造专用于 AI 大模型的芯片。
他们走了一条独特的路线:只能跑Transformer的AI芯片,并且采用了ASIC的设计方案。目前,市面几乎所有方案都对AI模型广泛支持,而他们从2022年底,就笃定Transformer模型将会统治整个市场,认为GPU在性能升级上的速度太慢了,只有走特化的ASIC芯片这条路才能实现性能上的飞跃。
历经两年,今年6月27日,Etched 推出了自己的第一款 AI 芯片 Sohu,成为了世界第一款专用于 Transformer 计算的芯片。
它运行大模型的速度比英伟达H100要快20倍,比今年3月才推出的顶配芯片B200还要快上超过10倍。一个搭载八片Sohu芯片的服务器,可以取代整整160个英伟达H100 GPU。大大降低成本的同时,也不会有性能损失。
由于Sohu仅支持一种算法,所以绝大多数的控制流模块都可以被剔除,芯片可以集成更多的数学计算单元,在算力利用率上可以达到90%以上,而GPU却只能做到30%。对于一个规模不算大的设计团队而言,维护单一架构的软件栈明显压力也更小。
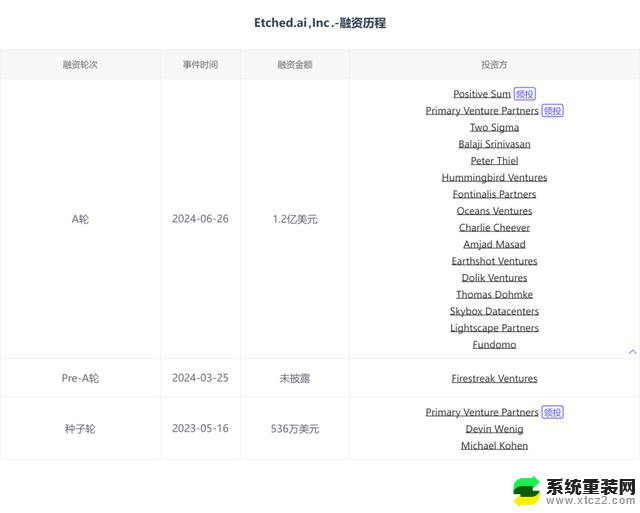
在Sohu芯片发布的同时,Etched也宣布已完成了1.2亿美元的 A 轮融资,由 Primary Venture Partners 和 Positive Sum Ventures 共同领投。
本轮融资的主要投资者包括硅谷知名投资人Peter Thiel、加密数字货币交易平台Coinbase前首席技术官及前a16z普通合伙人Balaji Srinivasan、GitHub 首席执行官 Thomas Dohmke、Cruise 联合创始人 Kyle Vogt 和 Quora 联合创始人 Charlie Cheever等等。
奥特曼投资的AI芯片独角兽Cerebras Systems拟冲刺IPO
成立于2015年的Cerebras Systems最独特的地方在于,他们的芯片和主流的英伟达GPU大相径庭。过去,芯片在摩尔定律的牵引下越做越小,以英伟达H100为例,814平方毫米的核心面积上拥有800亿晶体管。
而Cerebras的AI芯片,则选择将一整张芯片越做越大,号称“造出了世界上最大面积芯片”。据介绍,Cerebras开发的WSE 3芯片由整张晶圆切割,比盘子还大,需要人用双手捧起来。一张WSE 3芯片,在46000多平方毫米的核心面积上拥有40000亿晶体管(是H100的50倍)。
Cerebras宣称,他们的芯片可以训练的 AI 大模型规模,比目前业界顶尖大模型(如OpenAI 的GPT-4或Google的Gemini)还要大10倍。
今年8月27日,Cerebras Systems宣布推出AI推理服务Cerebras Inference,号称“全球最快”。据官网介绍,该推理服务在保证精度的同时,速度比英伟达的服务快20倍;其处理器内存带宽是英伟达的7000倍,而价格仅为GPU的1/5,性价比提高了100倍。Cerebras Inference还提供多个服务层次,包括免费、开发者和企业级,满足从小规模开发到大规模企业部署的不同需求。
联合创始人兼CEOAndrew Feldman拥有斯坦福大学MBA学位,首席技术官Gary Lauterbach被公认为业界顶尖的计算机架构师之一。2007年,两人一起创办了微型服务器公司SeaMicro,并由AMD在2012年以3.34亿美元收购,两人随之加入了AMD。

据外媒披露,Cerebras Systems已秘密申请在美国IPO,最快2024年10月上市。目前,这家公司已融资7.2亿美元,估值约为42亿到50亿美元,其中,最大的个人投资者之一是OpenAI的首席执行官山姆•奥特曼(Sam Altman)。据报道,奥特曼参与了Cerebras 的8100万美元D轮融资。
芯片传奇大神加盟的Tenstorrent,要成为英伟达的“平替”
在2021年之前,Tenstorrent还是一家名不见经传的公司。不过,随着被誉为“硅仙人”的半导体行业大神级人物吉姆・凯勒(Jim Keller)宣布加入该公司并担任首席技术官兼总裁,这家公司一时名声大噪。
吉姆·凯勒从业历程堪称计算机行业历史。1998-1999年,吉姆·凯勒在AMD操刀了支撑速龙的K7/K8架构;2008-2012年,在苹果牵头研发了A4、A5处理器;2012-2015年,在AMD主持K12 ARM项目、Zen架构项目;2016-2018年,在特斯拉研发FSD自动驾驶芯片,2018-2020年,在Intel参与神秘项目。
吉姆·凯勒加盟Tenstorrent,希望为英伟达昂贵的GPU提供“平替”。他认为,英伟达并没有很好地服务于某些市场,而这些市场恰恰是Tenstorrent所要夺取的。
Tenstorrent 称,其 Galaxy 系统的效率是英伟达DGX的三倍,成本低 33%,后者是世界上最受欢迎的 AI 服务器。
据报道,Tenstorrent 有望在今年年底前发布其第二代多用途 AI 处理器。根据 Tenstorrent去年秋天的最新路线图,该公司打算发布其Black Hole独立AI处理器和Quasar低功耗低成本小芯片,用于多小芯片 AI 解决方案。
该公司声称其即将推出的处理器提供的性能效率可与英伟达的 AI GPU 相媲美。同时,Tenstorrent 表示,其架构对内存带宽的消耗低于竞争对手,这是其更高效率和更低成本的关键原因。
Tentorrent芯片主要特点是其100多个内核中的每个内核都有小型CPU,即“大脑中的大脑”,内核将能够自行“思考”,决定先处理哪些数据,或者是否放弃某些被认为不必要的任务,从而提高整体效率。
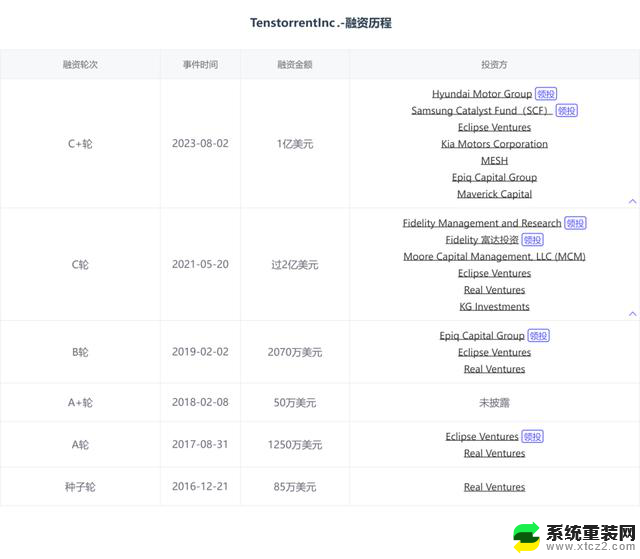
截至目前,Tentorrent已经完成至少6轮融资。此前,Tentorrent的投资方以风投为主,也就是在吉姆·凯勒加盟之后,公司在2023年8月完成了新一轮1亿美元的融资,投资方中开始出现了产业资本——现代汽车集团和三星旗下风投公司Samsung Catalyst Fund。
软银打折收购Graphcore,打造英伟达的竞争对手
Graphcore成立于2016年,由CTO Simon Knowles和CEO Nigel Toon创立。公司致力于开发Intelligence Processing Unit(IPU),这是一种专门为人工智能和机器学习设计的处理器,具有独特的架构和优势,例如大规模并行的MIMD架构、高内存带宽和紧密耦合的本地分布式SRAM等。
Graphcore 陆续推出了多款基于IPU的产品,如GC200 IPU处理器、Bow IPU等,并不断进行技术升级和改进。
不过,今年7月,这家正处于困境的英国AI芯片企业已被软银收购。
根据协议,Graphcore将成为软银的全资子公司,继续以现有名称运营。报道称,整个交易总额可能达到约4亿英镑(约合5亿美元,35.60亿元人民币),比Graphcore上轮融资时估值28亿美元缩水82%左右,实际软银仅用2折价值买下Graphcore。
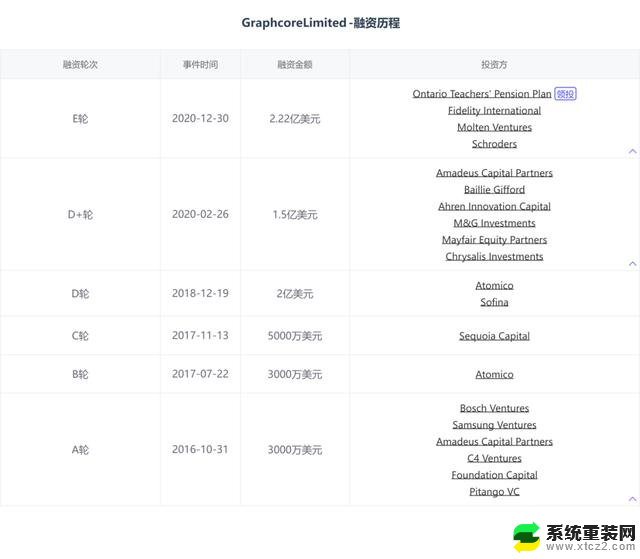
Graphcore 曾一度被视为“英国版英伟达”。然而自 2020 年以来,该企业未获得新的投资,也丢失了来自微软的重要订单,这使其资金紧张、运营困难,未能跟上AI芯片领域的大势。同时,美国对中国 AI 半导体的出口管制持续收紧,也影响Graphcore在中国的发展,最终不得不选择退出中国市场,并损失总收入的四分之一。
此次收购Graphcore不仅巩固了软银在AI芯片领域的地位,也是孙正义AI战略的重要一步。
前谷歌工程师成立Groq,创造出新物种LPU
Groq在今年8月宣布完成6.4亿美元D轮融资,投资方包括贝莱德、思科投资、三星催化基金等,估值达到28亿美元。
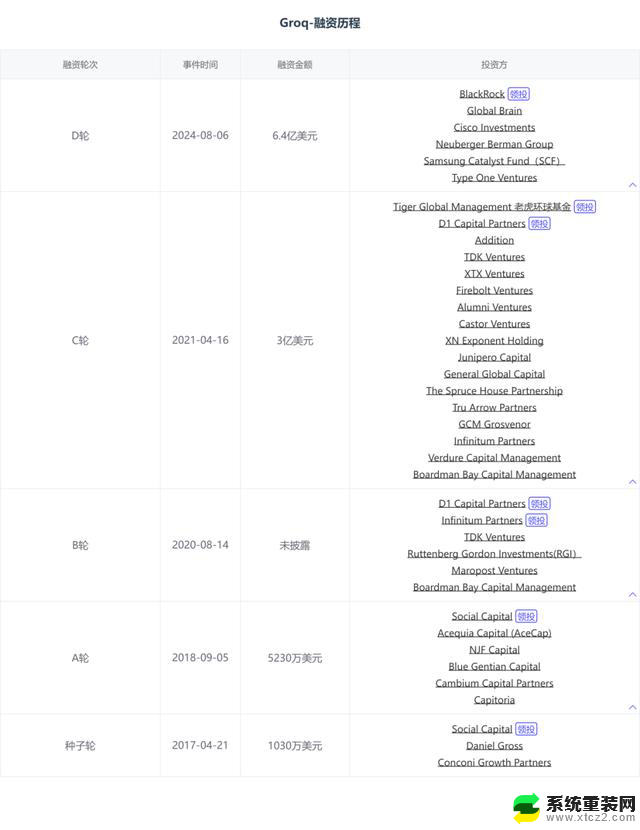
这家公司由前谷歌工程师Jonathan Ross于2016年创立,声称其语言处理单元硬件LPU可以运行现有的GenAI模型,如GPT-4,速度将提升十倍,而能耗仅为十分之一。该公司利用Meta的Llama 2创造了一个新的大型语言模型(LLM)性能记录,即每用户每秒300个令牌(Token)。
相对于GPU的多功能性,LPU虽然在语言处理方面表现出色,但其应用范围较窄。这限制了它们在更广泛的 AI 任务范围内的通用性。此外,作为新兴技术,LPU 还没有得到社区的广泛支持,可用性也面临挑战。
Groq计划在2025年第一季度末部署超过10.8万个LPU,这是除主要科技巨头之外最大的人工智能推理部署。
本文源自创业邦
谁能成为英伟达平替?找到最适合的替代品相关教程
- 英伟达或将停产RTX 4080显卡,Super系列或成替代选择
- 英伟达与软银合作打造日本最强AI计算机,孙正义后悔错失成为英伟达最大股东机会
- 时代更替!英伟达将被纳入道指,取代英特尔,市场震荡或将再次来临
- 微软、苹果、英伟达市值争夺战!15分钟内谁将成为“一哥”?
- CPU核心哪家强?英伟达:揭秘英伟达CPU核心的强大性能
- 英伟达AI PC芯片发布:整合Cortex-X5 CPU及Blackwell GPU内核2022最新
- 华西证券深度报告:谁是国产英伟达?探讨中国GPU巨头
- 英伟达再创历史新高,考验将在二季度到来:英伟达二季度能否继续创造历史新高?
- 破局AI,联想携手英伟达开启新纪元,能否超越华为?
- 最贵ST股”退市:“中国英伟达”的可耻落幕,股民遗憾告别
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐