最强AI芯片英伟达H200发布,HBM容量提升76%,大模型性能提升90%

11月14日消息,英伟达(Nvidia)于当地时间13日上午在 “Supercomputing 23”会议上正式发布了全新的H200 GPU,以及更新后的GH200 产品线。
其中,H200依然是建立在现有的 Hopper H100 架构之上,但增加了更多高带宽内存(HBM3e),从而更好地处理开发和实施人工智能所需的大型数据集,使得运行大模型的综合性能相比前代H100提升了60%到90%。而更新后的GH200,也将为下一代 AI 超级计算机提供动力。2024 年将会有超过 200 exaflops 的 AI 计算能力上线。
H200:HBM容量提升76%,大模型性能提升90%
具体来说,全新的H200提供了总共高达141GB 的 HBM3e 内存,有效运行速度约为 6.25 Gbps,六个 HBM3e 堆栈中每个 GPU 的总带宽为 4.8 TB/s。与上一代的H100(具有 80GB HBM3 和 3.35 TB/s 带宽)相比,这是一个巨大的改进,HBM容量提升了超过76%。官方提供的数据显示,在运行大模型时,H200相比H100将带来60%(GPT3 175B)到90%(Llama 2 70B)的提升。


虽然H100 的某些配置确实提供了更多内存,例如 H100 NVL 将两块板配对,并提供总计 188GB 内存(每个 GPU 94GB),但即便是与 H100 SXM 变体相比,新的 H200 SXM 也提供了 76% 以上的内存容量和 43 % 更多带宽。
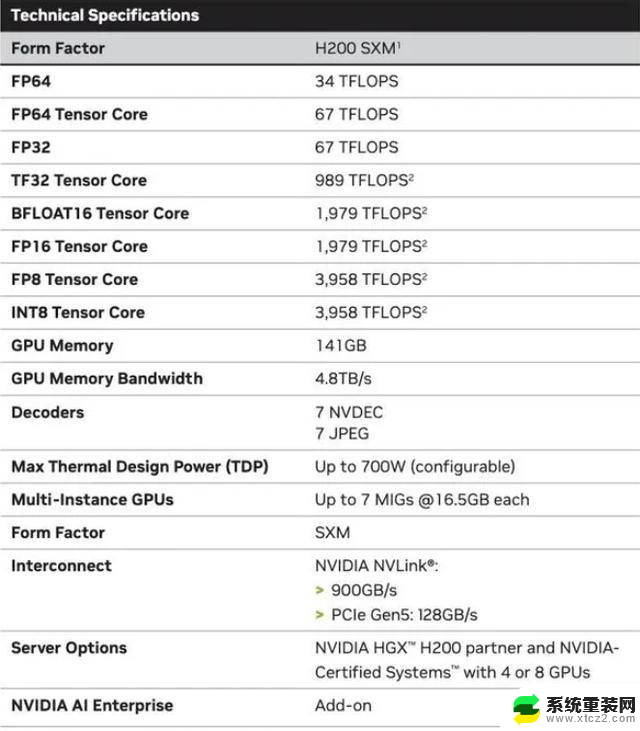
需要指出的是,H200原始计算性能似乎没有太大变化。英伟达展示的唯一体现计算性能的幻灯片是基于使用了 8 个 GPU的HGX 200 配置,总性能为“32 PFLOPS FP8”。而最初的H100提供了3,958 teraflops 的 FP8算力,因此八个这样的 GPU 也提供了大约32 PFLOPS 的 FP8算力。
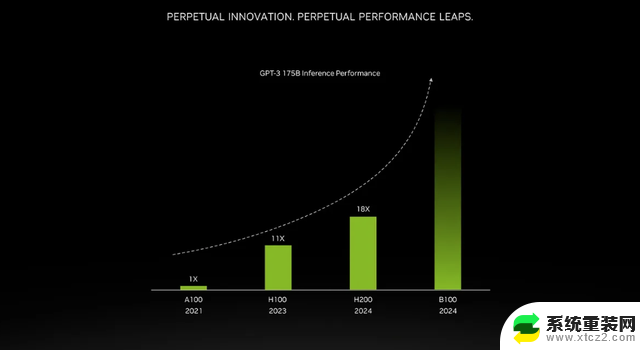
那么更多的高带宽内存究竟带来了哪些提升呢?这将取决于工作量。对于像 GPT-3 这样的大模型(LLM)来说,将会大大受益于HBM内存容量增加。英伟达表示,H200在运行GPT-3时的性能,将比原始 A100 高出 18 倍,同时也比H100快11倍左右。还有即将推出的 Blackwell B100 的预告片,不过目前它只包含一个逐渐变黑的更高条,大约达到了H200的两倍最右。
不仅如此,H200和H100是互相兼容的。也就是说,使用H100训练/推理模型的AI企业,可以无缝更换成最新的H200芯片。云端服务商将H200新增到产品组合时也不需要进行任何修改。
英伟达表示,通过推出新产品,他们希望跟上用于创建人工智能模型和服务的数据集规模的增长。增强的内存能力将使H200在向软件提供数据的过程中更快速,这个过程有助于训练人工智能执行识别图像和语音等任务。
“整合更快、更大容量的HBM內存有助于对运算要求较高的任务提升性能,包括生成式AI模型和高效能运算应用程序,同时优化GPU使用率和效率”,NVIDIA高性能计算产品副总裁Ian Buck表示。
英伟达数据中心产品负责人迪翁·哈里斯(Dion Harris)表示:“当你看看市场上正在发生的事情,你会发现模型的规模正在迅速扩大。这是我们继续迅速引进最新和最优秀技术的又一个例子。”
预计大型计算机制造商和云服务提供商将于2024年第二季度开始使用H200。英伟达服务器制造伙伴(包括永擎、华硕、戴尔、Eviden、技嘉、HPE、鸿佰、联想、云达、美超威、纬创资通以及纬颖科技)可以使用H200更新现有系统,而亚马逊、Google、微软、甲骨文等将成为首批采用H200的云端服务商。
鉴于目前市场对于英伟达AI芯片的旺盛需求,以及全新的H200增加了更多的昂贵的HBM3e内存,因此H200的价格肯定会更昂贵。英伟达没有列出它的价格,但上一代H100价格就已经高达25,000美元至40,000美元。
英伟达发言人Kristin Uchiyama指出,最终定价将由英伟达制造伙伴制定。
至于H200推出后,会不会影响H100生产,Kristin Uchiyama则表示:“你会看到我们全年的整体供应量有所增加”。
一直以来,英伟达的高端AI芯片被视为高效处理大量数据和训练大型语言模型、AI生成工具最佳选择,在发表H200之际,AI公司仍在市场上拼命寻求A100/H100芯片。市场关注的焦点仍在于,英伟达能否向客户提供足够多的供应,以满足市场需求。因此,H200是否还是会像H100一样供不应求?对此NVIDIA并没有给出答案。
不过,明年对GPU买家来说可能将是一个更有利时期,据《金融时报》8月报导曾指出,NVIDIA计划在2024年将H100产量提升三倍,产量目标将从2023年约50万个增加至2024年200万个。但生成式AI仍在蓬勃发展,未来需求也可能会更大。
比如最新推出的GPT-4大约是在10000-25000块A100上训练的;Meta的AI大模型需要大约21000块A100;Stability AI用了大概5000块A100;Falcon-40B的训练,用了384块A100。
根据马斯克的说法,GPT-5可能需要30000-50000块H100。摩根士丹利的说法是25000个GPU。
Sam Altman否认了在训练GPT-5,但却提过“OpenAI的GPU严重短缺,使用我们产品的人越少越好”。
当然,除了英伟达之外,AMD和英特尔也在积极的进入AI市场与英伟达展开竞争。此前AMD推出的MI300X就配备192GB的HBM3和5.2TB/s的显存带宽,这将使其在容量和带宽上远超H200。
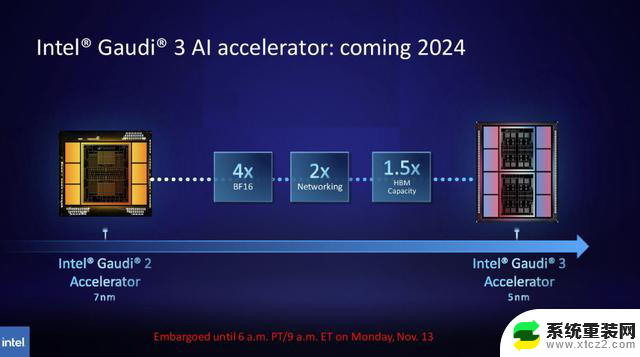
同样,英特尔也计划提升Gaudi AI芯片的HBM容量,最新公布的信息显示,Gaudi 3基于5nm工艺,在BF16工作负载方面的性能将是Gaudi 2的四倍,网络性能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。正如我们在下图中所看到的,Gaudi 3转向了具有两个计算集群的基于chiplet的设计,而不是英特尔为Gaudi 2使用的单芯片解决方案。
全新GH200超级芯片:为下一代 AI 超级计算机提供动力
除了全新的H200 GPU之外,英伟达还带来了更新后的GH200超级芯片。它使用NVIDIA NVLink-C2C芯片互连,结合了最新的H200 GPU 和 Grace CPU(不清楚是否为更新一代的),每个 GH200超级芯片还将包含总计 624GB 的内存。

作为对比,上一代的GH200则是基于H100 GPU和 72 核的Grace CPU,提供了96GB 的 HBM3 和 512 GB 的 LPDDR5X 集成在同一个封装中。
虽然英伟达并未介绍GH200超级芯片当中的Grace CPU细节,但是英伟达提供了GH200 和“现代双路 x86 CPU”之间的一些比较。可以看到,GH200带来了ICON性能8倍的提升,MILC、Quantum Fourier Transform、RAG LLM Inference等更是带来数十倍乃至百倍的提升。
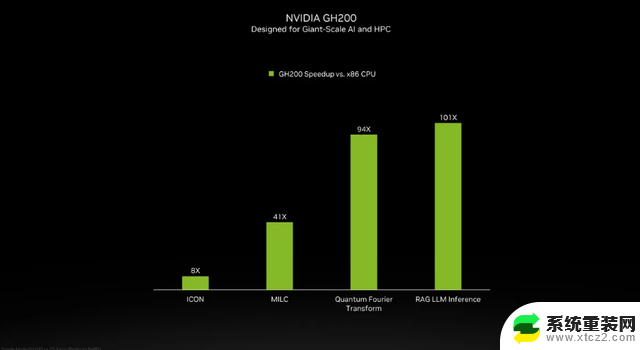
但需要指出的是,其中提到了加速与“非加速系统”。这意味着什么?我们只能假设 x86 服务器运行的是未完全优化的代码,特别是考虑到人工智能世界正在快速发展,并且优化方面似乎定期出现新的进展。
全新的GH200 还将用于新的 HGX H200 系统。据说这些与现有的 HGX H100 系统“无缝兼容”,这意味着 HGX H200 可以在相同的安装中使用,以提高性能和内存容量,而无需重新设计基础设施。
据介绍,瑞士国家超级计算中心的阿尔卑斯超级计算机(Alps supercomputer)可能是明年第一批投入使用的基于GH100的Grace Hopper 超级计算机之一。第一个在美国投入使用的 GH200 系统将是洛斯阿拉莫斯国家实验室的 Venado 超级计算机。德克萨斯高级计算中心 (TACC) Vista 系统同样将使用刚刚宣布的 Grace CPU 和 Grace Hopper 超级芯片,但尚不清楚它们是基于 H100 还是 H200。

目前,即将安装的最大的超级计算机是Jϋlich超级计算中心的Jupiter 超级计算机。它将容纳“近”24000 个 GH200 超级芯片,总共 93 exaflops 的 AI 计算(大概是使用 FP8,虽然大多数 AI 仍然使用 BF16 或 FP16)。它还将提供 1 exaflop 的传统 FP64 计算。它将使用具有四个 GH200 超级芯片的“Quad GH200”板。
总的来说,英伟达预计这些新的超级计算机的安装将在未来一年左右实现超过 200 exaflops 的 AI 计算性能。
编辑:芯智讯-浪客剑
最强AI芯片英伟达H200发布,HBM容量提升76%,大模型性能提升90%相关教程
- 英伟达新款芯片Blackwell问世,AI性能最高跃升30倍,革新性能再进一步
- AMD发布Instinct MI325X/MI355X AI加速器,代际性能升级强势对标H200
- 英伟达AI PC芯片发布:整合Cortex-X5 CPU及Blackwell GPU内核2022最新
- 刚刚!英伟达重磅发布:全新显卡性能再升级,震撼科技界
- 高通确认骁龙6s Gen 3为增强版695:提升CPU、GPU和AI性能,性能大幅提升
- AMD Ryzen Threadripper 7000系列:今年秋季发布,单核性能提升高达20%!
- 微软发布PowerToys 0.74:升级Text Extractor等,提升文本提取能力
- CPU核心哪家强?英伟达:揭秘英伟达CPU核心的强大性能
- 英伟达与软银合作打造日本最强AI计算机,孙正义后悔错失成为英伟达最大股东机会
- 微软新装备:内置英伟达GB200 AI芯片的服务器亮相,性能更强劲
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐
系统教程推荐
- 1 windows密码存储位置 win10账户密码存储位置在哪
- 2 红警ol可以在电脑上玩吗 电脑上玩红警OL的方法
- 3 电脑网页清理缓存怎么操作 多种方式快速清理浏览器缓存
- 4 联想笔记本电脑无线投屏到电视 联想电脑无线投屏到电视
- 5 电脑上所有word都被锁定怎么解除 word文档被保护无法修改
- 6 windows激活错误代码0xc004f074 Windows 10激活失败错误代码0xC004F074
- 7 win10软件不显示图标 Win10桌面图标显示不正常怎么处理
- 8 win10怎么给电脑分盘 Windows10怎么分区硬盘
- 9 电脑上的系统监视器是什么 电脑监视器的启动步骤
- 10 win10没有开始按钮 Win10系统开始菜单不见了怎么恢复