英伟达推出大模型加速包,Llama2推理速度翻倍
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
大模型的推理速度,仅仅一个月就提高了一倍!
英伟达近日官宣给H100推出了“鸡血包”——专用于LLM推理的加速程序。
或许这下可以不用空等明年才能交付的GH200了(手动狗头)。
GPU的运算能力一直影响着大模型的表现,无论是硬件提供者还是使用者都希望能算得更快些。
而作为大模型背后硬件的最大供应商,英伟达一直在研究怎么给大模型硬件加速。
通过与多家AI公司合作,英伟达终于推出了大模型推理优化程序TensorRT-LLM(暂且简称TensorRT)。
TensorRT不仅能让大模型的推理速度翻番,使用起来也十分方便。
无需深入了解C++和CUDA,也能快速定制优化策略,在H100上更快地跑大模型。
英伟达科学家范麟熙(Jim Fan)转发并评论称,英伟达的“另一项优势”就是可以最大化利用GPU性能的配套软件。
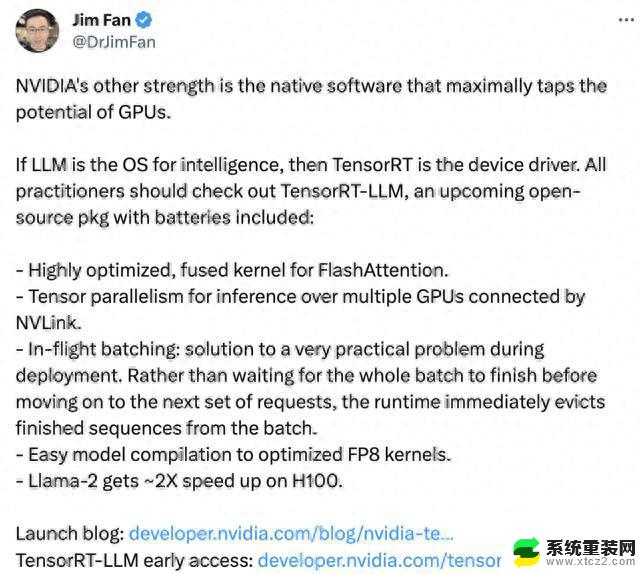
英伟达通过软件给产品打鸡血,仿佛在实践老黄的那句“买的越多省的越多”。但这也并不妨碍有人嫌贵:

除了价格,也有网友对其运行效果提出了质疑:

到底是不是真的有效可能还需要继续检验,我们先来具体了解一下TensorRT。
大模型推理速度翻倍TensorRT-LLM优化之后的H100,跑大模型到底有多快呢?
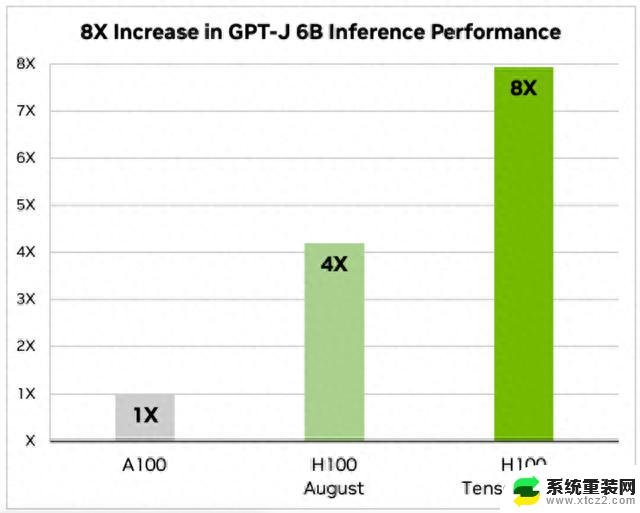
英伟达的通告中给出了Llama 2和GPT-J-6B两种模型的数据。
在优化后的H100上,跑Llama 2的推理速度则是A100的4.6倍、八月份未优化版H100的1.77倍。

而GPT-J-6B的推理速度是A100上的8倍、八月未优化版的2倍。
TensorRT还提供了开源的模块化Python API,根据不同LLM的需求,可以快速定制优化方案。
这个API将深度学习编译器、内核优化、预/后处理和多节点通信功能集成到了一起。
其中针对GPT(2/3)、Llama等常见模型,还有已经定制好的版本,可以“开箱即用”。
通过TensorRT中最新的开源AI内核,开发者还可以对模型自身进行优化。其中就包括了让Transformer大大提速的注意力算法FlashAttention。

那么TensorRT又是如何对LLM推理速度进行优化的呢?
首先要得益于TensorRT对多节点协同工作方式进行了优化。
像Llama这样庞大的模型,在单卡上是跑不起来的,需要多块GPU一起跑才能带动。
过去,这一工作需要人们手工把模型拆开来实现。
而有了TensorRT,系统可以自动化地对模型进行拆分,并通过NVLink在多GPU间高效运行。

其次,TensorRT还利用了一种名为动态批处理的优化调度技术。
LLM在推理过程中,实际上是在多次执行模型迭代。
动态批处理技术会将已完成的序列立即踢出,而不是等待整批任务完成后再处理下一组请求。
实际测试中,动态批处理将LLM的GPU请求吞吐量减少了一半,大大降低了运行成本。

另一个关键点则是将16位精度浮点数转换为8位精度,从而降低内存消耗。
FP8与训练阶段的FP16相比消耗的资源更低,同时精确度又高于INT-8,在提高性能的同时不影响模型的准确性。
通过Hopper Transformer引擎,FP16到FP8的转化编译由系统自动完成,无需人工对模型中的任何代码进行修改。
目前,TensorRT-LLM的早鸟版已经可以下载,正式版将于几周内推出并集成到NeMo框架中。
One More Thing每当大事件出现,总少不了“列文虎克”的身影。
英伟达的公告中提到了“在与Meta等AI头部公司合作”,但没有提及OpenAI。
从这则通告中,就有网友发现了这个华点,并发到了OpenAI论坛上:

你还期待老黄带给我们什么样的“惊喜”呢?
参考链接:
https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
英伟达推出大模型加速包,Llama2推理速度翻倍相关教程
- 英伟达官宣开源TensorRT-LLM,推理能力飙升8倍!
- NVIDIA-Merlin: 基于GPU的推荐系统训练和推理全套方案——加速推荐系统训练和推理的最佳选择
- 微软推出XOT方法,加强AI推理能力,解决复杂问题并扩展语言模型
- 英伟达第三季度营收181.2亿美元,净利润92.43亿美元:业绩强劲助推英伟达创佳绩
- 英伟达黄仁勋:AI推理未来,降低算力成本是关键
- 英伟达RTX50显卡推迟上市以提升良率台媒报道
- 英特尔推进x86指令集重大变革,AMD态度成关键
- 国产CPU研究:国产化加速推进,计算机运算和控制核心
- 微软推出AI模型“MAI-1”与谷歌、OpenAI竞争:最新消息
- 英伟达推出全新NVIDIA app:玩家的终极游戏与创作工具,让你尽情享受游戏创作的乐趣
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐