英伟达H100软件加持下AI性能比MI300X快47%

12月14日消息,AMD于本月初推出了其最强的AI芯片Instinct MI300X,其8-GPU服务器的AI性能比英伟达H100 8-GPU高出了60%。对此英伟达于近日发布了一组最新的H100与MI300X的性能对比数据,展示了H100如何使用正确的软件提供比MI300X更快的AI性能。
根据AMD此前公布的数据显示,MI300X的FP8/FP16性能都达到了英伟达(NVIDIA)H100的1.3倍,运行Llama 2 70B和FlashAttention 2 模型的速度比H100均快了20%。在8v8 服务器中,运行Llama 2 70B模型,MI300X比H100快了40%;运行Bloom 176B模型,MI300X比H100快了60%。
但是。需要指出的是,AMD在将MI300X 与 英伟达H100 进行比较时,AMD使用了最新的 ROCm 6.0 套件中的优化库(可支持最新的计算格式,例如 FP16、Bf16 和 FP8,包括 Sparsity等),才得到了这些数字。相比之下,对于英伟达H100则并未没有使用英伟达的 TensorRT-LLM 等优化软件加持情况下进行测试。
AMD对于英伟达H100测试的隐含声明显示,使用vLLM v.02.2.2推理软件和英伟达DGX H100系统,Llama 2 70B查询的输入序列长度为2048,输出序列长度为128。
而英伟达最新公布的对于DGX H100(带有8个NVIDIA H100 Tensor Core GPU,带有80 GB HBM3)测试,带有公开的NVIDIA TensorRT LLM软件,v0.5.0用于Batch-1,v0.6.1用于延迟阈值测量。工作量详细信息与脚注与AMD之前的测试相同。
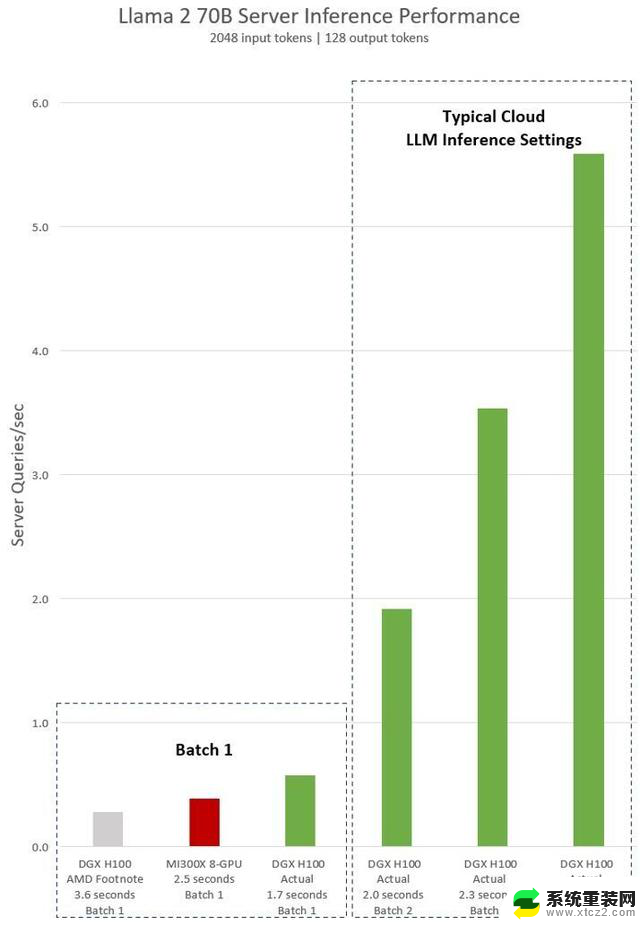
结果显示,与 AMD展示的MI300X 8-GPU服务器性能相比,英伟达DGX H100 服务器在使用优化的软件加持后,速度提高了 2 倍多,相比 AMD MI300X 8-GPU 服务器快了47%。
DGX H100 可以在1.7 秒内处理单个推理任务。为了优化响应时间和数据中心吞吐量,云服务为特定服务设置了固定的响应时间。这使他们能够将多个推理请求组合成更大的“Batch”,并增加服务器每秒的总体推理次数。MLPerf 等行业标准基准测试也使用此固定响应时间指标来衡量性能。
响应时间的微小权衡可能会导致服务器可以实时处理的推理请求数量产生不确定因素。使用固定的 2.5 秒响应时间预算,英伟达DGX H100 服务器每秒可以处理超过 5 个 Llama 2 70B 推理,而Batch-1每秒处理不到一个。
显然,英伟达使用这些新的基准测试是相对公平的,毕竟AMD也使用其优化的软件来评估其GPU的性能,所以为什么不在测试英伟达H100时也这样做呢?
要知道英伟达的软件堆栈围绕CUDA生态系统,经过多年的努力和开发,在人工智能市场拥有非常强大的地位,而AMD的ROCm 6.0是新的,尚未在现实场景中进行测试。
根据AMD之前透露的信息显示,其已经与微软、Meta等大公司达成了很大一部分交易,这些公司将其MI300X GPU视为英伟达H100解决方案的替代品。
AMD最新的Instinct MI300X预计将在2024年上半年大量出货,但是。届时英伟达更强的H200 GPU也将出货,2024下半年英伟达还将推出新一代的Blackwell B100。另外,英特尔也将会推出其新一代的AI芯片Gaudi 3。接下来,人工智能领域的竞争似乎会变得更加激烈。
编辑:芯智讯-浪客剑
英伟达H100软件加持下AI性能比MI300X快47%相关教程
- 一文看懂英伟达系列显卡特点及性能参数对比 - 全面解析英伟达显卡性能差异
- CPU核心哪家强?英伟达:揭秘英伟达CPU核心的强大性能
- 英伟达新款芯片Blackwell问世,AI性能最高跃升30倍,革新性能再进一步
- 微软新装备:内置英伟达GB200 AI芯片的服务器亮相,性能更强劲
- 英伟达与软银合作打造日本最强AI计算机,孙正义后悔错失成为英伟达最大股东机会
- 破局AI,联想携手英伟达开启新纪元,能否超越华为?
- 英伟达坚持了16年的CUDA,到底是什么?CUDA是什么意思?
- 刚刚!英伟达重磅发布:全新显卡性能再升级,震撼科技界
- 最强AI芯片英伟达H200发布,HBM容量提升76%,大模型性能提升90%
- 英伟达将在日本建AI工厂网络,优先考虑GPU需求,加速日本AI产业发展
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐