只有27亿参数,性能却高25倍!微软发布Phi-2,开创新纪元!
Phi-2是基于微软的Phi-1.5开发而成,可自动生成文本/代码、总结文本、数学推理等功能。
虽然Phi-2的参数很小,性能却优于130亿参数的Llama-2和70亿参数的Mistral,以及谷歌最新发布的Gemini Nano 2。
值得一提的是,Phi-2没有进行过RLHF(人类反馈强化学习)和指令微调只是一个基础模型,但在多个任务评测中,其性能可以媲美或超过25倍参数的模型。
目前,微软已经开源了Phi-1.5和Phi-1,帮助开发者们深度研究和应用小参数模型。
Phi-1.5开源地址:https://huggingface.co/microsoft/phi-1_5
Phi-1开源地址:https://huggingface.co/microsoft/phi-1
Phi-1.5论文地址:https://arxiv.org/abs/2309.05463
目前,大模型界有一个很怪的现象,就是出的模型参数越来越大,几百亿参数只能算刚入门,上千亿的比比皆是,有的模型甚至已经达到上万亿。
参数高的模型并非不好,而是要看应用场景。对于像微软、OpenAI、百度、科大讯飞这样的基础模型服务商来说,参数越高覆盖能力就越广。例如,ChatGPT已经进化到多模态,除了生成文本,还能生成图片听懂声音等。
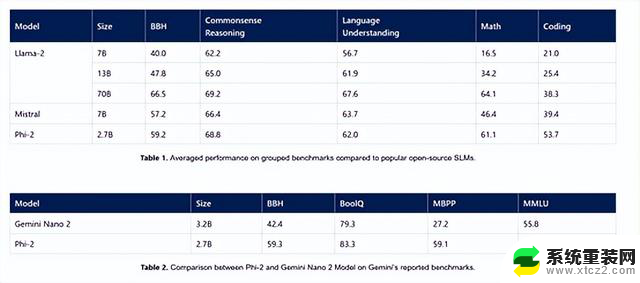
Phi-2评测数据
但参数高的模型同样也有很多缺点:过拟合,如果训练数据较差会出现能力不升反降的现象;算力成本巨大,用户每一次的提问都像是在“燃烧金钱”;预训练时间长,每一次模型的迭代需要耗费大量训练时间。
调优困难,高参数的模型拥有庞大且难控制的神经元,想进行部分功能调优和控制非常困难,最近变懒的GPT-4便是最好的案例。
所以,微软开发Phi系列模型的主要目的是研究。小参数模型如何在保证功能的前提下,也能与大参数的模型相媲美甚至超越,这对于企业和应用者来说是一个双赢的局面。
Phi-2简单介绍
Phi-2和Phi-1.5一样采用了24层的Transformer架构,每个头的维度为64,并使用了旋转嵌入等技术来提升模型性能。
Phi-2只是一个基础模型,没有进行过人类反馈强化学习和指令微调。但在文本生成、数学推理、代码编程方面丝毫不比大参数的模型差,甚至比他们更好。

训练数据和流程方面,Phi-2使用了1.4T超高质量的“教科书级”数据进行了预训练,并非是网络爬取的杂乱、黑箱数据。微软表示,这也是小参数模型比大参数模型性能高的关键原因之一。
Phi-2 在 96 个 A100 GPU上一共训练了14天。
Phi-2实验数据
微软在MMLU、BBH、PIQA、WinoGrande、ARC easy、Challenge、SIQA和GSM8k等主流测试平台对Phi-2进行了测试。
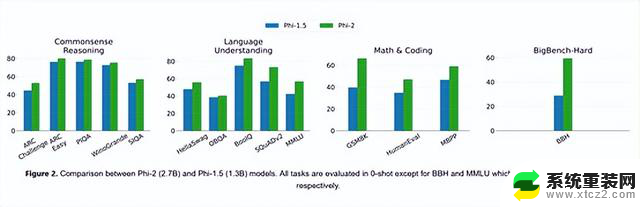
数据显示,在各种聚合基准上的测试超过了,Mistral -7B和Llama-2-13B。
值得一提的是,在多步推理测试任务中,例如,编码和数学,Phi-2的性能超过了700亿参数的Llama-2。
本文素材来源微软官网、Phi-1.5论文,如有侵权请联系删除
END
只有27亿参数,性能却高25倍!微软发布Phi-2,开创新纪元!相关教程
- 微软联手法国AI初创Mistral,共同投资21亿美元开启欧洲AI新纪元
- 微软发布Win11 Dev 26120.2213预览版更新,体验最新系统功能特性
- 微软市值创新高达22.5万亿,比尔盖茨成为大输家!
- 3万亿盛宴!微软奇迹催生,科技版图再添浓墨重彩,引领科技行业进入新纪元
- 微软2024年将发布具有“突破性”AI功能的Windows版本,引领智能化时代的突破之作!
- 微软发布Win11 23H2,赶快更新系统,核心功能国区无法使用
- 微软发布全新的必应搜索引擎:功能更强大、交互更智能
- 微软发布Windows 11 系统更新KB5035950:Copilot全新功能大揭秘
- 纽约时报起诉微软和OpenAI侵权:损失数十亿美元
- 微软新品发布会,一文阅览全部新品,全面解读微软最新产品发布会
- 如何正确更新NVIDIA显卡驱动以提升性能和稳定性?
- 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 芯片巨头AMD将全球裁员4%,涉及员工约1000人,原因和影响分析
- 也来凑热闹 微软游戏部门负责人谈Xbox掌机:探讨微软最新游戏主机发展趋势
- 微软发布Win11 27749 Canary预览版:增强讲述人功能优化
微软资讯推荐
- 1 微软最新营销暗示Xbox品牌“不再被游戏机硬件限制”,全新游戏体验尽在掌握
- 2 微软斯宾塞暗讽PS5 Pro:1000美元的主机无法推动市场增长
- 3 AMD确认裁员4%,以便将资源投向“最大的增长机会”:公司精准战略调整!
- 4 如何有效解决CPU温度过高的问题与方法,降低CPU温度的有效技巧
- 5 如何查看和识别显卡型号的详细步骤与方法,快速识别您电脑显卡型号
- 6 高通自研Oryon CPU:性能“至尊”之选
- 7 如何查看显卡型号及其详细信息的方法指南:轻松掌握显卡型号查询技巧
- 8 详细步骤教你如何重装Windows系统,让电脑恢复原装
- 9 详细指南:如何轻松查看显卡温度及其影响 - 完整教程和技巧
- 10 搭载NVIDIA RTX的AI工作站,加速并优化AI开发2021最新
win10系统推荐
系统教程推荐
- 1 window10在线升级 Windows10怎么升级系统
- 2 win11系统耳机没声音 Win11耳机插入电脑没声音怎么解决
- 3 win11给管理员 权限 如何在Windows 11中找到管理员权限设置
- 4 win11arm版本安装应用程序失败 Win11 24H2 安装 9 月更新卡在 35%
- 5 win11画图等比例缩放 win11屏幕分辨率和缩放比例设置方法
- 6 win11系统蓝屏系统无法正常启动 Win11电脑蓝屏无法开机解决方法
- 7 win11状态已隔离 Win11 24H2版内存隔离功能开启方法
- 8 win11无法访问 错误代码:0x80004005 Windows错误代码0x80004005的解决技巧
- 9 win11如何获得管理员权限运行 win11管理员权限怎么开启
- 10 win11的日期怎样设置有节假日标志 开启系统日历的节假日显示功能